

Every company contends with data quality, and in its pursuit they often commit substantial resources to manage their master and reference data. Remarkably, quite a bit of confusion exists around exactly what these are and how they differ. And since they provide context to business activity, this confusion can undermine any data quality initiative.
Here are amalgams of the prevailing definitions, which seem meaningful at first glance:

Sound familiar? In this article, I will discuss some tools and techniques for naming and defining terms that explain how these definitions actually create confusion. Although there is no perfect solution, I will share the terms and definitions that have helped me guide data initiatives, processes, technologies, and governance over the course of my career.
What’s in a Name?
Unique and self-explanatory names save time and promote common understanding. Naming, however, is nuanced in that words are often overloaded with multiple meanings. The word “customer,” for instance, often means very different things to people in the finance, sales, or product departments. There are also conventions that, while not exactly precise, have accumulated common understanding over time. The term “men’s room,” for example, is understood to mean something more specific than a room (it has toilets); yet something less specific than men’s (it’s also available to boys).
They’re both “master”
The term “master” data derives from the notion that each individually identifiable thing has a corresponding, comprehensive and authoritative record in the system. The verb to master means to gain control of something. The word causes confusion, however, when used to distinguish master data from reference data. If anything, reference data is the master of master data, as it categorizes and supplies context to master data. The dependency graph below demonstrates that master data may refer to and thus depend on reference data (red arrow), but not the other way around:
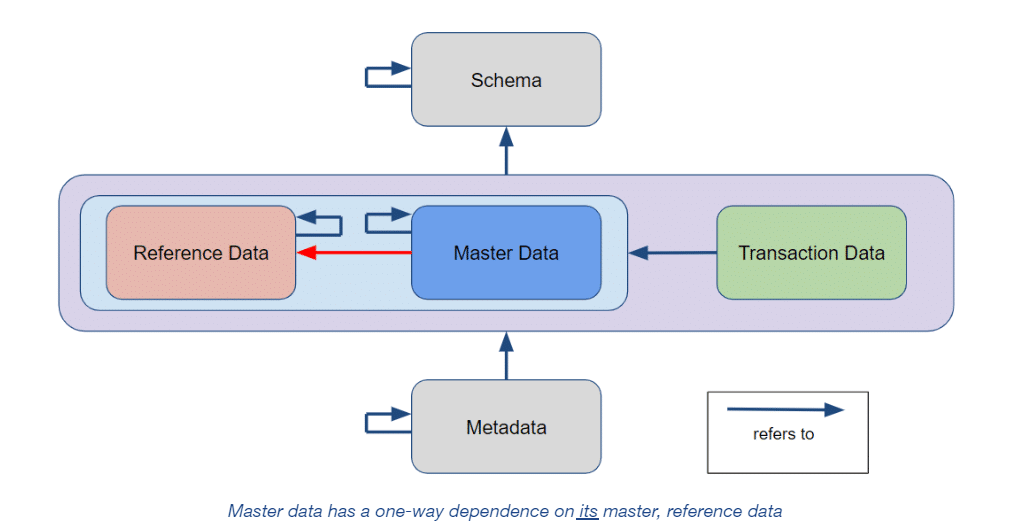
They’re both “reference”
The name “reference data” also makes sense in isolation. It evokes reference works like dictionaries, which are highly curated by experts and typically used to look up individual terms rather than being read from beginning to end. But reference can also mean the act of referring, and in practice, master data has just as many references to it as reference data.
So without some additional context, these terms are problematic in relation to each other.

It is what it is
Although we could probably conjure better terms, “Master Data” and “Reference Data” have become universal standards with innumerable citations. Any clarification provided by new names would be offset by their incompatibility with the consensus

Pluralizations R Us
Whenever possible, it’s best to express terms in the singular rather than the plural since the singular form refers to the thing itself, while the plural form denotes a set. That’s why dictionaries always define the singular form and provide the plural forms as an annotation. Consider the following singular and plural terms and definitions:

* Note that entity is used in the entity-relationship sense, where it denotes a type of thing rather than an identifiable instance of a thing.
The singular term “entity” works better for our purposes since the job at hand is to classify each entity as reference or master, rather than some amorphous concept of data. In our case, classifying each individual entity informs its materialized design in a database, its quality controls, and its integration process. The singular also makes it more natural to articulate relationships between things, as demonstrated by these awkward counterexamples:
“One bushels contains many apples.”
“Each data contains one or more entities.”
Good Things Come in Threes
Trying to describe the subject area with just two terms, master and reference, falls short because the relationship between the two cannot be fully understood without also defining the class that includes them both. For example, some existing definitions specify a “disjoint” relationship in which an entity can belong to either reference or master data, but not both. This can be represented as a diagram or tree:
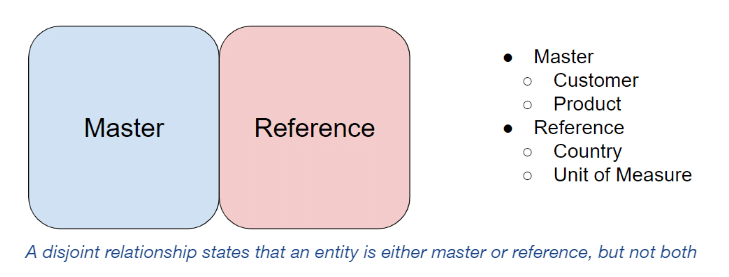
The conception is incomplete because the class that contains both reference and master data is missing. Are master data and reference data equal siblings among other data categories, as demonstrated below?
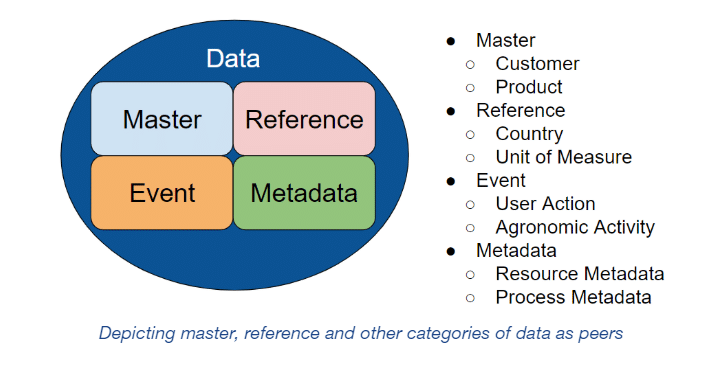
That’s not pragmatic, since it falsely implies that master and reference data have no more potential for common governance and technology than, say, weblogs and image metadata. We can remedy that by subsuming master and reference data within an intermediate class, which must still be named, defined, and assigned the common characteristics shared by master and reference data.

Some definitions posit an inclusion or containment relationship in which reference data is a subset of master data, rather than a disjoint peer. This approach, however, omits the complement–the master data which is not reference data.
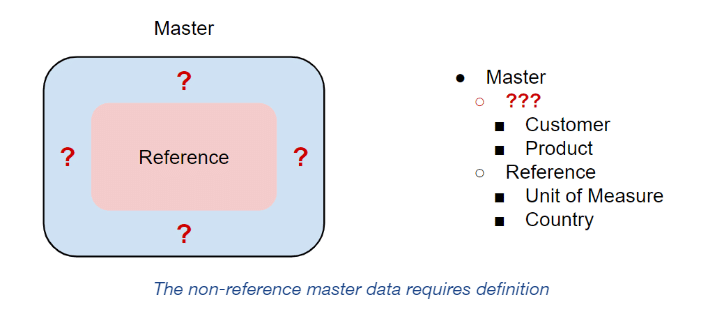
Any vocabulary that doesn’t specify the combination of master and reference data will be incomplete and potentially confusing.

It’s Just Semantics
Generally speaking, there are two broad categories of definitions: extensional and intensional.
Extensional Definitions
An extensional definition simply defines an entity by listing all of its instances, as in the following example:

This is out of the question for defining reference or master data, as each has too many entities and regularly occurring additions. Imagine how unhelpful and immediately obsolete the following definition would be:

A variation of this approach, ostensive definition, uses partial lists as examples. These are often used for “type” entities that nominally classify other things:
![]()
Ostensive definitions, unlike extensional definitions, can withstand the addition of new instances. They do not, however, explain why their examples satisfy the term. In fact, ostensive definitions are used primarily for situations in which it’s hard to formulate a definition that can stand on its own. Therefore both extensive and ostensive definitions are inadequate since they fail to provide a rationale to distinguish reference from master data.
Intensional Definitions
Intensional definitions, on the other hand, define things by their intrinsic properties and do not require lists of instances. The following definition of mineral, for example, does not list any actual minerals:

With that definition, we can examine the properties of quartz, for example, and determine that it meets the necessary and sufficient conditions to be deemed a mineral. Now we’re getting somewhere, and existing definitions have naturally used this approach.
Unfortunately, the conditions put forth in the existing definitions of master and reference data can describe either, rather than one or the other. The following table shows that every condition in the intensional definitions of master and reference data applies to both terms:


How can you categorize the product entity, for example, when it adheres to both definitions? It definitely conforms to the definition of master–a core thing shared across an enterprise. But it also conforms to reference, as it’s often reasonably stable and simply structured, used to categorize other things (sales), provides a list of permissible values (order forms), and corresponds to external databases (vendor part lists). I could make the same case for almost any entity categorized as master or reference, and this is where the definitions fail.
Celebrate Diversity
Although they share the same intrinsic qualities, master and reference data truly are different and require separate terms and definitions. Their flow through a system and their respective quality control processes, for instance, are quite distinct.
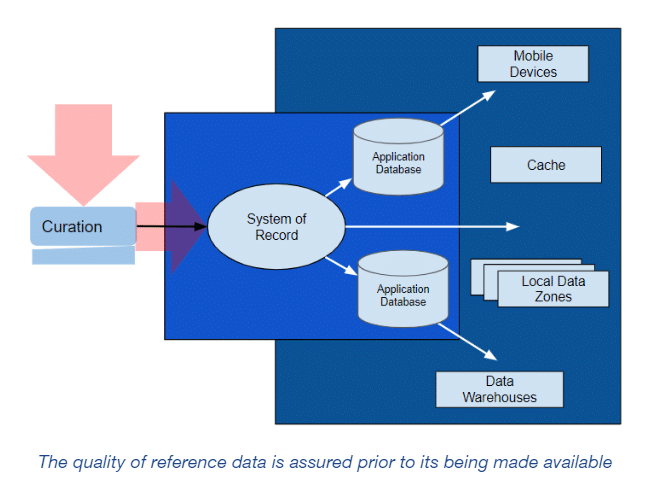
Reference data is centrally administered and stored. It is curated by an authoritative party before becoming available in its system of record, and only then is it copied to application databases or the edge. An organization, for instance, would never let a user casually add a new unit of measure or a new country.
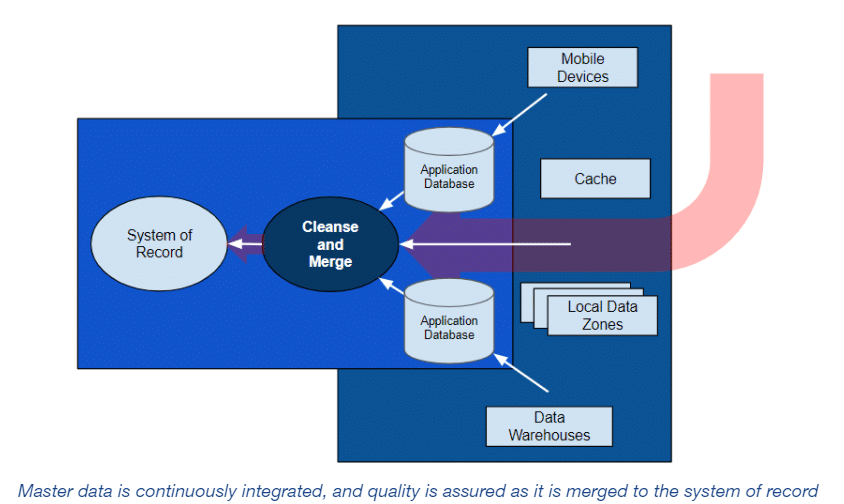
Master data, on the other hand, is often regularly added and modified in various distributed systems. New users register online, sales systems acquire new customers, organizations hire and fire employees, etc. The data comes in from the edge during the normal course of business, and quality is enforced as it is merged into the systems of record.
Companies must distinguish between master and reference data to ensure their quality and proper integration.

Turn The Beat Around
It’s entirely reasonable and common to define things by their intrinsic qualities and then use those definitions to inform their use and handling. Intuition tells us that once we understand the characteristics of a class of data, we can assess how best to manage it. But since the characteristics of master and reference data overlap, we need to approach their definitions differently.
In software architecture and design, there’s a technique called Inversion of Control that reverses the relationship between a master module and the process it controls. It essentially makes the module subservient to the process. We can apply a similar concept here by basing our definitions on the processes required by the data, rather than trying to base the processes on insufficiently differentiated definitions. This allows us to pragmatically define terms that abide by the conclusions described above:
- Continue to use the industry-standard terms “master data” and “reference data.”
- Define terms in the singular form.
- Define a third concept that encompasses both categories.
- Eschew extensive and ostensive definitions, and use intensional definitions that truly distinguish the concepts
With all that out of the way, here are the definitions that have brought clarity and utility to my work with master and reference data. I’ve promoted the term “core” from an adjective of master data to a first-class concept that expresses the superclass encompassing both master and reference entities.

With core defined, we can use a form of intensional definition called genus differentia for reference and master data. Genus differentia definitions have two parts. The first, genus, refers to a previously defined class to which the concept belongs–core entity, in our case. The rest of the definition, the differentia, describes what sets it apart from others in its class. We can now leverage our definition of core entity as the genus, allowing the data flow to provide the differentia. This truly distinguishes reference and master.

We can base the plural terms on the singular ones:

Conclusion
This article has revealed several factors that have handicapped our understanding of master and reference data:
- The names and prevailing definitions insufficiently distinguish the concepts because they apply to both.
- The plural form of a given concept obscures its definition.
- Master data and reference data are incompletely described without a third class that contains both.
Although convention dictates retention of the terms “master” and “reference,” we achieve clarity by using genus differentia to demonstrate that while they are both classified as core entities, they are truly distinguished by their flow and quality requirements rather than any intrinsic qualities or purpose.
By Alan Freedman

Want to learn more about what we do at Semantic Arts? Contact us!
