
In 2013 marijuana became legal in Colorado and Washington. It did not escape the notice of our clients that all Semantic Arts staff are from those two states. Suspicions grew deeper when we told them about the large collaborative knowledge base called Freebase. The looks on their faces told us they were thinking about freebase. We were but a whisker away from the last straw on the day we introduced them to the idea of degeneracy. “No, no we insisted, we are talking about a situation that commonly arises in mathematics and computing where something is considered to be a degenerate case of something else”. That was a close call; fortunately, all that confusion was “just semantics”.
Today we explain the idea of degeneracy and why it is useful for computing and ontology.

Figure 1: Examples of Degeneracy
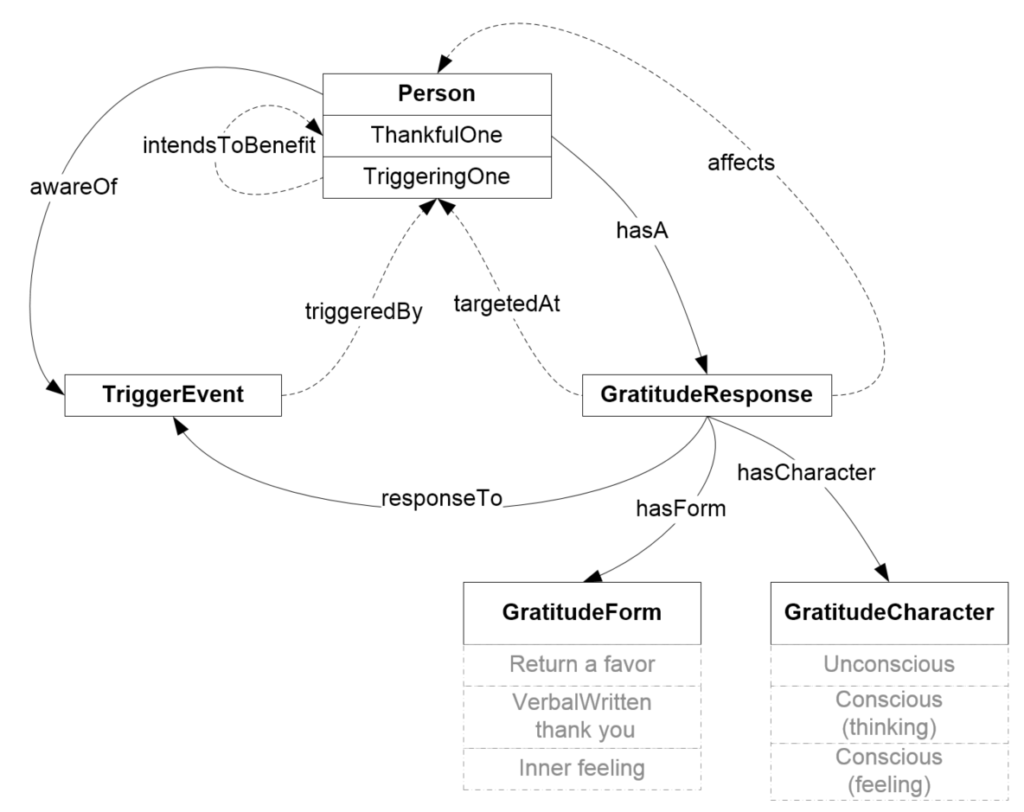
Examples of Degeneracy: A circle is defined to be the set of points that are equidistant from a given point. The radius of the circle is that distance. But what do you have if the radius is zero? You have the set of points that are zero length from a given point, which is to say just that one point. In mathematics we would say a point is the degenerate case of a circle.
We all know what a rectangle is, but what happens if the width of an otherwise ordinary rectangle is zero? Then you just get a single line segment. Again, we say that a line segment is a degenerate case of a rectangle.
A set normally has two or more members, otherwise what is the point of calling it a set? Yet, the need for speaking of and representing sets that have 0 or 1 elements often arises. It happens so frequently that they have names: empty set and singleton set. They are degenerate cases of a set.
An example of a more complex structure than a set, is a process that consists of any number of tasks, and some ordering indicating what tasks must be done before what other tasks. However, sometimes, during computation or analysis, it can be convenient or even necessary to allow for processes that have zero tasks, or just one task. We could refer to such processes as empty or singleton processes. These are degenerate cases of a process that ordinarily should have two or more tasks.
What do all these examples have in common? What can we say about every case of degeneracy?
Definition
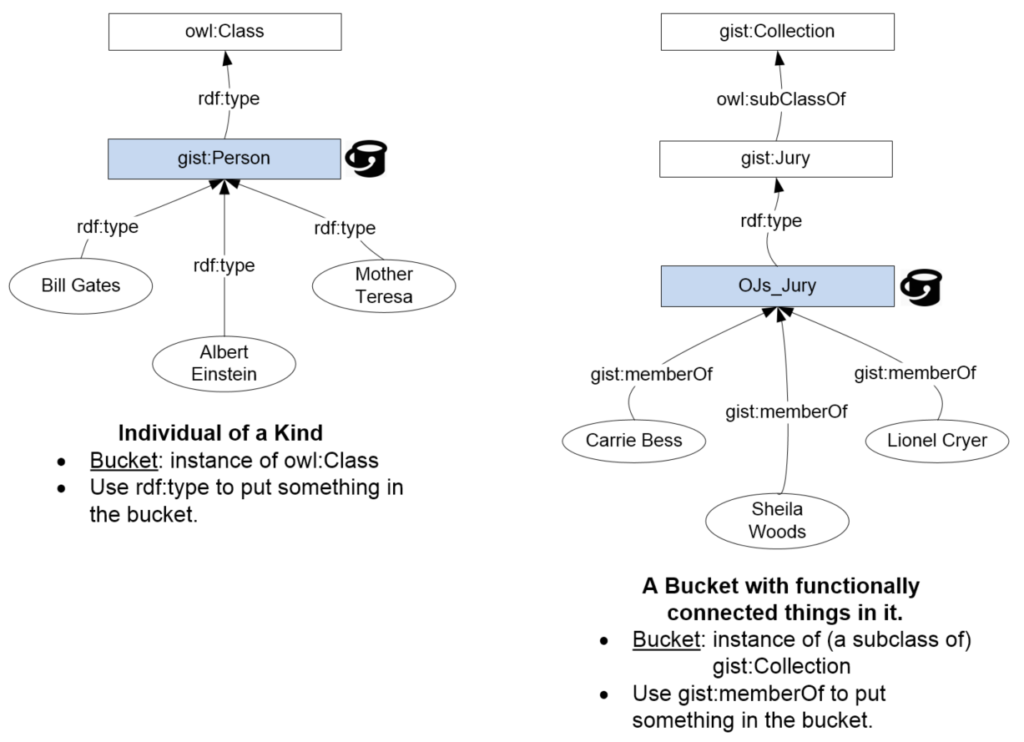
I propose the following as a working definition of degeneracy. We say that an X is a degenerate case of a Y when:
- Strictly speaking, an X can be seen to be an example of a Y
- a point is a circle with radius equal to zero
- a line segment is a rectangle with one of the dimensions having zero length.
- An X is substantially simpler than a Y, some of the essence of being a Y is missing.
- The much simpler nature of an X results in the X having lost so much of the essence of being a Y, that in most circumstances, no one would even think to call the X a Y. Ordinarily:
- no one would think to refer to a point as a circle.
- no one would think to refer to nothing at all as a set.
- no one would think to refer to doing a single thing (much less nothing) as a process
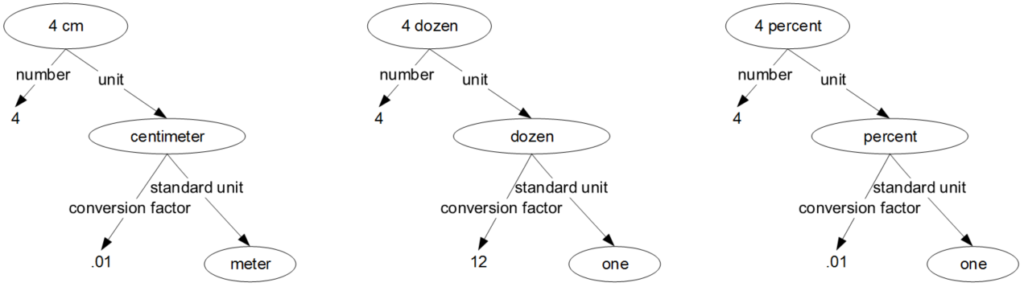
Figure 2: Number units as Degenerate Units of Measure
Why bother?
It might seem rather silly, or something that only mathematicians would bother about, but it turns out that in computing, degeneracy is very important. Let’s say you want to compute the average of an arbitrary set of numbers. In every day parlance, it makes no sense to speak of the average of a single number. However, you want your algorithm to work if you get a set that happens to only have one number in it. You therefore want to be able to pass the algorithm a set with one element in it.
When processes are being executed, tasks are being done, so a set of tasks may dwindle down to one and then to zero. If you want the algorithm to work, it needs to understand what it means to have a process with 1 or zero tasks. When there are no tasks left, the task is to do nothing. Sometimes it is even helpful to consciously put a ‘do nothing’ task in a plan or process.
Generally speaking, degenerate cases are useful when you want computational infrastructure to still work on the edge cases.
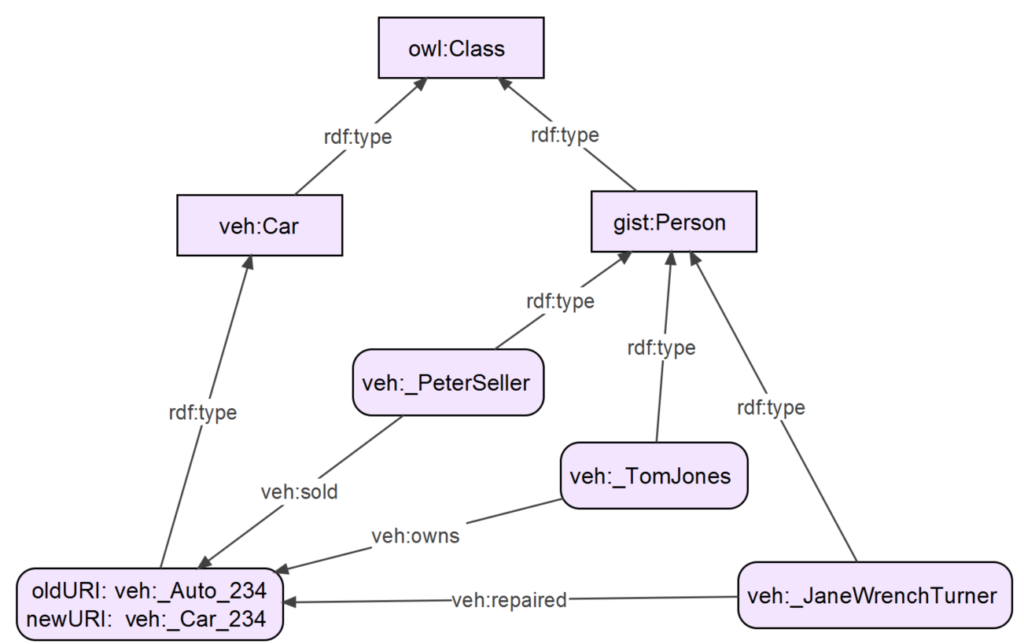
The most interesting example that I have seen of this in the context of ontology work arises in the context of doing unit conversions for physical quantities. For example, you convert 4 cm meters using a conversion factor of .01. You convert 3 kg to grams by using a conversion factor of 1000. We have an ontology for representing such physical quantities with units and conversion factors. Using this ontology, we have code to do units analysis and computing conversions.
It turns out to be convenient to give pure numbers ‘units’ just like we give physical quantities units. For example, a wine merchant might sell cases with 12 bottles each. A unit of ‘dozen’ would come in handy, with a conversion of 12. Another convenient number unit is percent with a conversion of .01. To convert 250% to the true number, you multiply 250 by .01 to get 2.5. To convert 4 dozen to the true number, you multiply 4 by 12 to get 48.
The is completely analogous to converting 250 cm to meters, you multiply 250 by .01 to get 2.5 meters. It turns out that you can represent pure numbers this way using units in a way that is exactly analogous to how your represent physical quantities like 4 cm and 5 watts. This means that the same code for doing units conversions on physical quantities with ordinary units also works for number units. A pure number like 48 represented as a 4 with the unit ‘dozen’ is a degenerate case of a physical quantity such as ‘250 cm’. Pure number units like dozen and percent are degenerate cases of ordinary physical units like cm or watt.
Go back and look at the previous section and check the extent to which pure numbers and number units fit the definition of degeneracy.
- Strictly speaking a pure number like ‘4 dozen’ can be seen as a physical quantity, in the sense that it can be represented exactly like one, with a unit and a number.
- Pure numbers are simpler than physical quantities because they are only numbers, very different from say 3 meters or 20 amperes.
- No one would normally think to refer to a pure number like 4 or 48 as something that had a unit attached to it. The essence that has been lost is to have a unit that changes the character from being a pure number. Number units like dozen and percent do not change the quantity from still just being a number. 4 dozen and 4 and 4% are all just numbers. Whereas the difference between 4 and 4 cm and 4 amperes is huge.
For a detailed look at number units see the blog: Quantities, Number Units and Counting

 be
be 
 Are you struggling with how to make best use of your company’s knowledge assets that have grown overly complex? Have you wondered how to blend the more informal taxonomic knowledge with the more formal ontological knowledge? This has been a real head-scratcher for us for quite a while now. We described some breakthroughs we have made in the past couple of years on this front in a
Are you struggling with how to make best use of your company’s knowledge assets that have grown overly complex? Have you wondered how to blend the more informal taxonomic knowledge with the more formal ontological knowledge? This has been a real head-scratcher for us for quite a while now. We described some breakthroughs we have made in the past couple of years on this front in a 