I’m at a graph conference. The general sense is that property graphs are much easier to get started with than Knowledge Graphs. I wanted to explore why that is, and whether it is a good thing.
It’s a bit of a puzzle to us, we’ve been using RDF and the Semantic Web stack for almost two decades, and it seems intuitive, but talking to people new to graph databases there is a strong preference to property graphs (at this point primarily Neo4J and TigerGraph, but there are others). – Dave McComb
Property Graphs
A knowledge graph is a database that stores information as digraphs (directed graphs, which are just a link between two nodes).

The nodes self-assemble (if they have the same value) into a completer and more interesting graph.
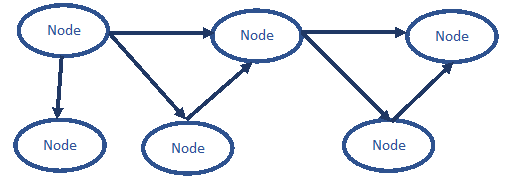
What makes a graph a “property graph” (also called a “labeled property graph”) is the ability to have values on the edges
Either type of graph can have values on the nodes, in a Knowledge Graph they are done with a special kind of edge called a “datatype Property.”
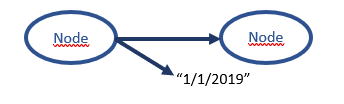
Here is an example of one of the typical uses for values on the edges (the date the edge was established). As it turns out this canonical example isn’t a very good example, in most databases, graph or otherwise, a purchase would be a node with many other complex relationships.
The better use of dates on the edges in property graphs are where there is what we call a “durable temporal relation.” There are some relationships that exist for a long time, but not forever, and depending on the domain are often modeled as edges with effective start and end dates (ownership, residence, membership are examples of durable temporal relations that map well to dates on the edges)
The other big use case for values on the edges which we’ll cover below.
The Appeal of Property Graphs
Talking to people and reading white papers, it seems the appeal of Property Graph data bases are in these areas:
- Closer to what programmers are used to
- Easy to get started
- Cool Graphics out of the box
- Attributes on the edges
- Network Analytics
Property Graphs are Closer to What Programmers are Used to
The primary interfaces to Property Graphs are json style APis, which developers are comfortable with and find easy to adapt to.
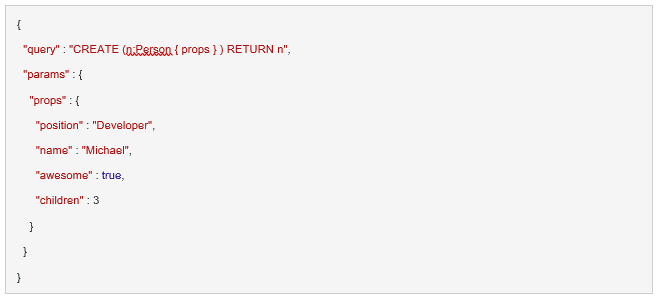
Easy to Get Started
Neo4J in particular have done a very good job of getting people set up and running and productive in short order. There are free versions to get started with, and well exercised data sets to get up and going rapidly. This is very satisfying for people getting started.
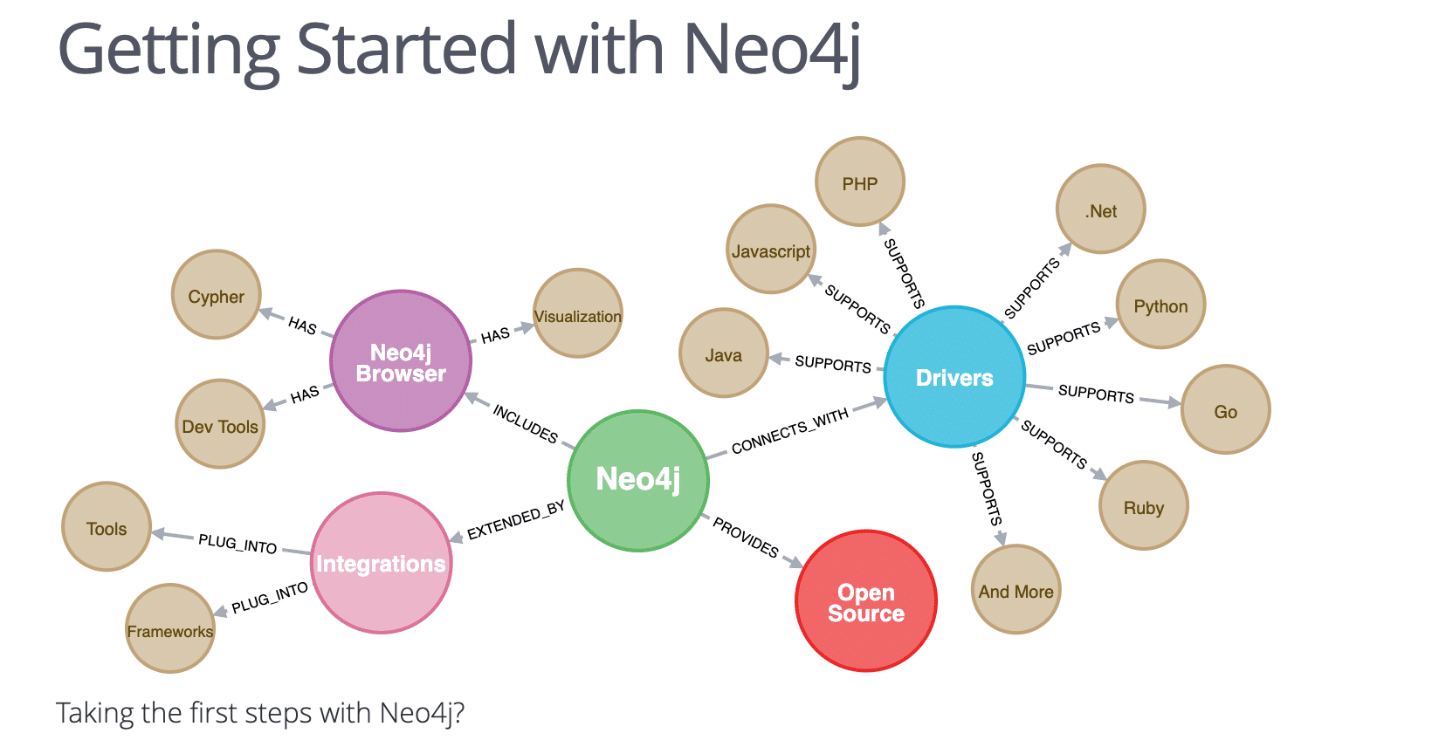
Cool Graphics Out of the Box
One of the striking things about Neo4J is their beautiful graphics

You can rapidly get graphics that often have never been seen in traditional systems, and this draws in the attention of sponsors.
Property Graphs have Attributes on the Edges
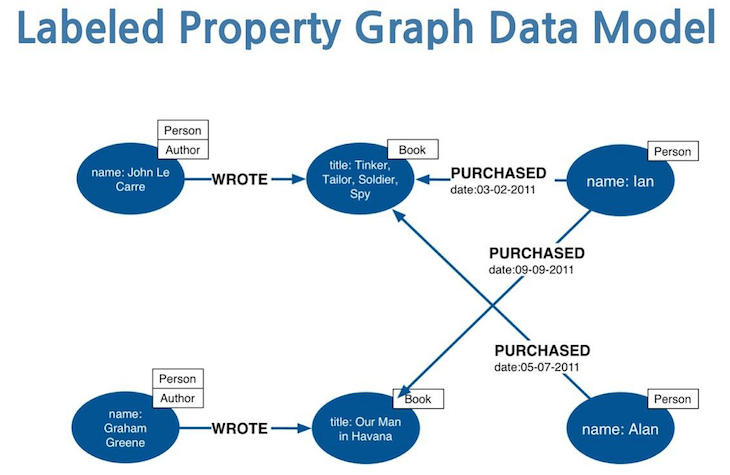
Perhaps the main distinction between Property Graphs and RDF Graphs is the ability to add attributes to the edges in the network. In this case the attribute is a rating (this isn’t a great example, but it was the best one I could find easily).
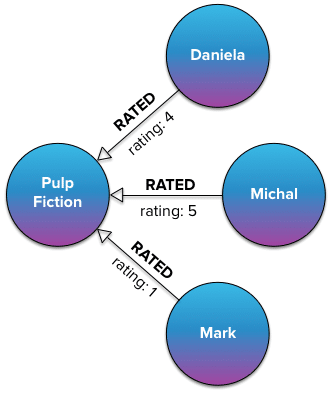
One of the primary use cases for attributes on the edges would be weights that are used in the evaluation of network analytics. For instance, a network representation of how to get from one town to another, might include a number of alternate sub routes through different towns or intersections. Each edge would represent a segment of a possible journey. By putting weights on each edge that represented distance, a network algorithm could calculate the shortest path between two towns. By putting weights on the edges that represent average travel time, a network algorithm could calculate the route that would take the least time.
Other use cases for attributes on the edges include temporal information (when did this edge become true, and when was is no longer true), certainty (you can rate the degree of confidence you have in a given link and in some cases only consider links that are > some certainly value), and popularity (you could implement the page rank algorithm with weights on the edges, but I think it might be more appropriate to put the weights on the nodes)
Network Analytics
There are a wide range of network analytics that come out of the box and are enabled in the property graph. Many do not require attributes on the edges, for instance the “clustering” and “strength of weak ties” suggested in this graphic can be done without attributes on the edges.
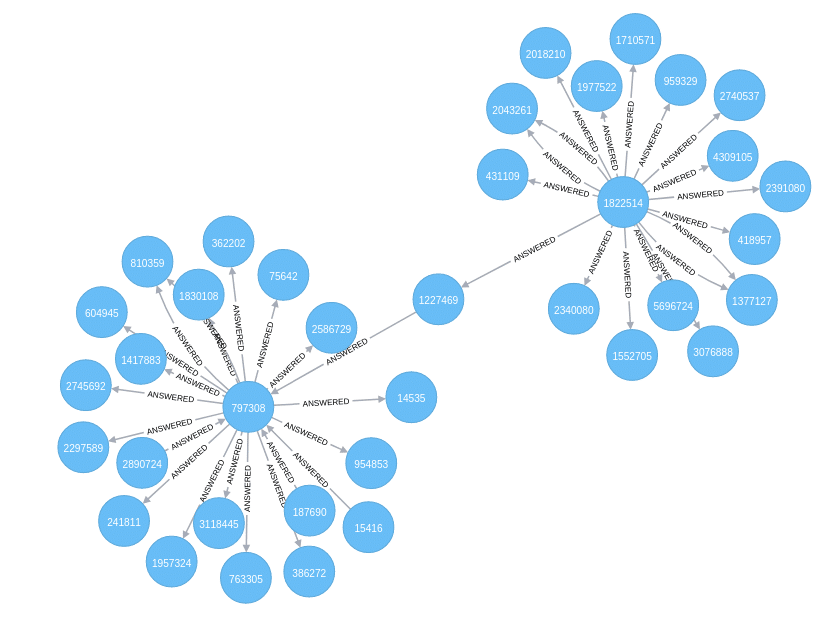
However, many of the network analytics algorithms can take advantage of and gain from weights on the edges.
Property Graphs: What’s Not to Like
That is a lot of pluses on the Property Graph side, and it explains their meteoric rise in popularity.
Our contention is that when you get beyond the initial analytic use case you will find yourself in a position of needing to reinvent a great body of work that already exists and have been long standardized. At that point if you have over committed to Property Graphs you will find yourself in a quandary, whereas if you positioned Property Graphs as a stepping stone on the way to Knowledge Graphs you will save yourself a lot unnecessary work.
Property Graphs, What’s the Alternative?
The primary alternative is an RDF Knowledge Graph. This is a graph database using the W3C’s standards stack including RDF (resource description framework) as well as many other standards that will be described below as they are introduced.
The singular difference is the RDF Knowledge Graph standards were designed for interoperability at web scale. As such all identifiers are globally unique, and potentially discoverable and resolvable. This is a gigantic advantage when using knowledge graphs as an integration platform as we will cover below.
Where You’ll Hit the Wall with Property Graphs
There are a number of capabilities, we assume you’ll eventually want to add on to your Property Graph stack, such as:
- Schema
- Globally Unique Identifiers
- Resolvable identifiers
- Federation
- Constraint Management
- Inference
- Provenance
Our contention is you could in principle add all this to a property graph, and over time you will indeed be tempted to do so. However, doing so is a tremendous amount of work, high risk, and even if you succeed you will have a proprietary home-grown version of all these things that already exist, are standardized and have been in large scale production systems.
As we introduce each of these capabilities that you will likely want to add to your Property Graph stack, we will describe the open standards approach that already covers it.
Schema
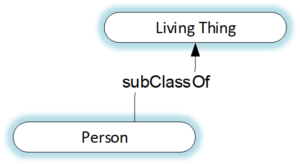
Property Graphs do not have a schema. While big data lauded the idea of “schema-less” computing, the truth is, completely removing schema means that a number of functions previously performed by schema have now moved somewhere else, usually code. In the case of Property Graphs, the nearest equivalent to a schema is the “label” in “Labeled Property Graph.” But as the name suggests, this is just a label, essentially like putting a tag on something. So you can label a node as “Person” but that tells you nothing more about the node. It’s easier to see how limited this is when you label a node a “Vanilla Swap” or “Miniature Circuit Breaker.”
Knowledge Graphs have very rich and standardized schema. One of the ways they allow you to have the best of both worlds, is unlike relational databases they do not require all schema to be present before any data can be persisted. At the same time when you are ready to add schema to your graph, you can do so with a high degree of rigor and go to as much or as little detail as necessary.
Globally Unique Identifiers
The identifiers in Property Graphs are strictly local. They don’t mean anything outside the context of the immediate database. This is a huge limitation when looking to integrate information across many systems and especially when looking to combine third party data.
Knowledge Graphs are based on URIs (really IRIs). Uniform Resource Identifiers (and their Unicode equivalent, which is a super set, International Resource Identifiers) are a lot like URLs, but instead of identifying a web location or page, they identify a “thing.” In best practices (which is to say 99% of all the extant URIs and IRIs out there) the URI/IRI is based on a domain name. This delegation of id assignment to organizations that own the domain names allows relatively simple identifiers that are not in danger of being mistakenly duplicated.
Every node in a knowledge graph is assigned a URI/IRI, including the schema or metadata. This makes discovering what something means as simple as “following your nose” (see next section)
Resolvable Identifiers
Because URI/IRIs are so similar to URLs, and indeed in many situations are URLs it makes it easy to resolve any item. Clicking on a URI/IRI can redirect to a server in the domain name of the URI/IRI, which can then render a page that represents the Resource. In the case of a schema/ metadata URI/IRI the page might describe what the metadata means. This typically includes both the “informal” definition (comments and other annotations) as well as the “formal” definition (described below).
For a data URI/IRI the resolution might display what is known about the item (typically the outgoing links), subject to security restrictions implemented by the owner of the domain. This style of exploring a body of data, by clicking on links and exploring is called “following your nose” and is a very effective way of learning a complex body of knowledge, because unlike traditional systems you do not need to know the whole schema in order to get started.
Property Graphs have no standard way of doing this. Anything that is implemented is custom for the application at hand.
Federation
Federation refers to the ability to query across multiple databased to get a single comprehensive result set. This is almost impossible to do with relational databases. No major relational database vendor will execute queries across multiple databases and combine the result (the result generally wouldn’t make any sense anyway as the schemas are never the same). The closest thing in traditional systems, is the Virtual Data P***, which allows some limited aggregation of harmonized databases.
The Property Graphs also have no mechanism for federation over more than a single in memory graph.
Federation is built into SPARQL (the W3C standard for querying “triple stores” or RDF based Graph Databases). You can point a SPARQL query at a number of databases (including relational databases that have been mapped to RDF through another W3C standard, R2RML).
Constraint Management
One of the things needed in a system that is hosting transactional updates, is the ability to enforce constraints on incoming transactions. Suffice it to say Property Graphs have no transaction mechanism and no constraint management capability.
Knowledge Graphs have the W3C standard, SHACL (SHApes Constraint Language) to specify constraints in a model driven fashion.
Inference
Inference is the creation of new information from existing information. A Property Graph creates a number of “insights” which are a form of inference, but it is really only in the heads of the persons running the analytics and interpreting what the insight is.
Knowledge Graphs have several inference capabilities. What they all share is that the result of the inference is rendered as another triple (the inferred information is another fact which can be expressed as a triple). In principle almost any fact that can be asserted in a Knowledge Graph can also be inferred, provided the right contextual information. For instance, we can infer that a class is a subclass of another class. We can infer that a node has a given property, we can infer that two nodes represent the same real-world items, and each of these inferences can be “materialized” (written) back to the database. This makes any inferred fact available to any human reviewing the graph, and process that acts on the graph, including queries.
Two of the prime creators of inferred knowledge are RDFS and OWL, the W3C standards for schema. RDFS provides the simple sort of inference that people familiar with Object Oriented programming might be familiar with, primarily the ability infer that a node that is a member of a class is also a member of any of its superclasses. A bit new to many people is the idea that properties can have superproperties, and that leads to inference at the instance level. If you make the assertion that you have a mother (property :hasMother) Beth, and then declare :hasParent to be a superproperty of :hasMother, the system will infer that you :hasParent Beth, and this process can be repeated by making :has Ancestor a superproperty of :hasParent. The system can infer and persist this information.
OWL (the Web Ontology Language for dyslexics) allows for much more complex schema definitions. OWL allows you to create class definitions from Booleans, and allows the formal definition of classes by creating membership definitions based on what properties are attached to nodes.
If RDFS and OWL don’t provide sufficient rigor and/or flexibility there are two other options, both rule languages and both will render their inferences as triples that can be returned to the triple store. RIF (the Rule Interchange Format) allow inference rules defined in terms of “if / then“ logic. SPARQL the above-mentioned query language can also be used to create new triples that can be rendered back to the triple store.
Provenance
Provenance is the ability to know where any atom of data came from. There are two provenance mechanisms in Knowledge Graphs. For inferences generated from RDFS or OWL definitions, there is an “explain” mechanism, which is decribed in the standards as “proof.” In the same spirit as a mathematical proof, the system can reel out the assertions including schema-based definitions as data level assertions that led to the provable conclusion of the inference.
For data that did not come from inference (that was input by a user, or purchased, or created through some batch process, there is a W3C standard, call PROV-O (the provenance ontology) that outlines a standard way to describe where a data set or even an individual atom of data came from.
Property Graphs have nothing similar.
Convergence
The W3C held a conference to bring together the labeled property graph camp with the RDF knowledge graph camp in Berlin in March of 2019.
One of our consultants attended and has been tracking the aftermath. One promising path is RDF* which is being mooted as a potential candidate to unify the two camps. There are already several commercial implementations supporting RDF*, even though the standard hasn’t even begun its journey through the approval process. We will cover RDF* in a subsequent white paper.
Summary
Property Graphs are easy to get started with. People think RDF based Knowledge Graphs are hard to understand, complex and hard to get started with. There is some truth to that characterization.
The reason we made the analogy to “training wheels” (or “stepping stones” in the middle of the article) is to acknowledge that riding a bike is difficult. You may want to start with training wheels. However, as you become proficient with the training wheels, you may consider discarding them rather than enhancing them.
Most of our clients start directly with Knowledge Graphs, but we recognize that that isn’t the only path. Our contention is that a bit of strategic planning up front, outlining where this is likely to lead gives you a lot more runway. You may choose to do your first graph project using a property graph, but we suspect that sooner or later you will want to get beyond the first few projects and will want to adopt an RDF / Semantic Knowledge Graph based system.

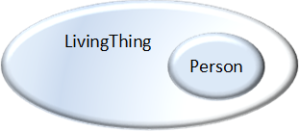
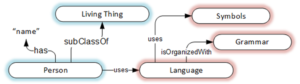
 Person learns language. We spend the early years of life learning vocabulary and grammar in order to generate and consume meaning. As a result of constantly engaging in semantic generation and consumption, most of us are semantic savants. This Meaning-First approach is our default until we are faced with capturing meaning in databases. We then revert to the Structure-First approach that has been beaten into our heads since Codd invented the relational model in 1970. This blog post presents Meaning-First data modeling for semantic knowledge graphs as a replacement to Structure-First modeling. The relational model was a great start for data management, but it is time to embrace a radical return to simplicity: Meaning-First data modeling.
Person learns language. We spend the early years of life learning vocabulary and grammar in order to generate and consume meaning. As a result of constantly engaging in semantic generation and consumption, most of us are semantic savants. This Meaning-First approach is our default until we are faced with capturing meaning in databases. We then revert to the Structure-First approach that has been beaten into our heads since Codd invented the relational model in 1970. This blog post presents Meaning-First data modeling for semantic knowledge graphs as a replacement to Structure-First modeling. The relational model was a great start for data management, but it is time to embrace a radical return to simplicity: Meaning-First data modeling.
 At Semantic Arts we often come across ontologies whose developers seem to take pride in the number of classes they have created, giving the impression that more classes equate to a better
At Semantic Arts we often come across ontologies whose developers seem to take pride in the number of classes they have created, giving the impression that more classes equate to a better 

 to make use of the data they have.
to make use of the data they have. a rallying point around which to gather and show our colors to the world. They are a way of showing membership in a group, or providing a warning. Which is why it is so unfortunate when we find flags in a data management system, because they are reduced to saying nothing. Let me explain.
a rallying point around which to gather and show our colors to the world. They are a way of showing membership in a group, or providing a warning. Which is why it is so unfortunate when we find flags in a data management system, because they are reduced to saying nothing. Let me explain. months. Both exercises reminded me that Data-Centric is not a simple technology upgrade. It’s going to take a great deal more to shift the status quo.
months. Both exercises reminded me that Data-Centric is not a simple technology upgrade. It’s going to take a great deal more to shift the status quo. PowerPoint slides that served to anchor, but it was much more a continual co-creation of a shared artifact.
PowerPoint slides that served to anchor, but it was much more a continual co-creation of a shared artifact.
 You may be wondering what some of our Data-Centric Conference panel topics will actually look like, what the discussion will entail. This article from Forbes is an interesting take on knowledge graphs and is just the kind of thing we’ll be discussing at the Data-Centric Conference.
You may be wondering what some of our Data-Centric Conference panel topics will actually look like, what the discussion will entail. This article from Forbes is an interesting take on knowledge graphs and is just the kind of thing we’ll be discussing at the Data-Centric Conference.