gistBFO: An Open-Source, BFO Compatible Version of gist
Dylan ABNEY a,1, Katherine STUDZINSKI a, Giacomo DE COLLE b,c, Finn WILSON b,c, Federico DONATO b,c, and John BEVERLEY b,c aSemantic Arts, Inc.
bUniversity at Buffalo
cNational Center for Ontological Research
ORCiD ID: Dylan Abney https://orcid.org/0009-0005-4832-2900, Katherine Studzinski https://orcid.org/0009-0001-3933-0643, Giacomo De Colle https://orcid.org/0000- 0002-3600-6506, Finn Wilson https://orcid.org/0009-0002-7282-0836, Federico Donato https://orcid.org/0009-0001-6600-240X, John Beverley https://orcid.org/0000- 0002-1118-1738
Abstract. gist is an open-source, business-focused ontology actively developed by Semantic Arts. Its lightweight design and use of everyday terminology has made it a useful tool for kickstarting domain ontology development in a range of areas including finance, government, and pharmaceuticals. The Basic Formal Ontology (BFO) is an ISO/IEC standard upper ontology that has similarly found practical application across a variety of domains, especially biomedicine and defense. Given its demonstrated utility, BFO was recently adopted as a baseline standard in the U.S. Department of Defense and Intelligence Community.
Because BFO sits at a higher level of abstraction than gist, we see an opportunity to align gist with BFO and get the benefits of both: one can kickstart domain ontology development with gist, all the while maintaining an alignment with the BFO standard. This paper presents such an alignment, which consists primarily of subclass relations from gist classes to BFO classes and includes some subproperty axioms. The union of gist, BFO, and this alignment is what we call “gistBFO.” The upshot is that one can model instance data using gist and then instances of gist classes can be mapped to BFO. This not only achieves compliance with the BFO standard; it also enables interoperability with other domains already modelled using BFO. We describe a methodology for aligning gist and BFO, provide rationale for decisions we made about mappings, and detail a vision for future development.
Keywords. Ontology, upper ontology, ontology alignment, gist, BFO
1. Introduction
In this paper, we present an alignment between two upper ontologies: gist and the Basic Formal Ontology (BFO). While both are upper ontologies, gist and BFO exhibit rather different formal structures. An alignment between these ontologies allows users to get the benefits of both.
An ontology is a representational artifact which includes a hierarchy of classes of entities and logical relations between them [1, p.1]. Ontologies are increasingly being used to integrate diverse sorts of data owing to their emphasis on representing implicit semantics buried within and across data sets, in the form of classes and logical relations among them [2]. Such formal representations facilitate semantic interoperability, where diverse data is connected by a common semantic layer. Ontologies have additionally proven valuable for clarifying the meanings of terms [3] and supporting advanced reasoning when combined with data, in the form of knowledge graphs [4].
The Basic Formal Ontology (BFO) is an upper-level ontology that is used by over 700 open-source ontologies [5]. It is designed to be very small, currently consisting only of 36 classes, 40 object properties, and 602 axioms [6]. BFO satisfies the conditions for counting as a top-level ontology, described in ISO/IEC 21838-1:2021: it is “…created to represent the categories…shared across a maximally broad range of domains” [7]. ISO/IEC 21838-2:2021 establishes BFO as a top-level ontology standard [8]. The BFO ecosystem adopts a hub-and-spokes strategy for ontology extensions, where classes in BFO form a hub, and new subclasses of BFO classes are made as spokes branching out from it. Interoperability between different ontologies can be preserved by linking up to BFO as a common hub. All classes in BFO are subclasses of bfo:Entity2 [9], which includes everything that has, does, or will exist. Within this scope, BFO draws a fundamental distinction with two classes: bfo:Continuant and bfo:Occurrent. Roughly, a continuant is a thing that persists over some amount of time, whereas an occurrent is something that happens over time [1]. A chef is an example of a continuant, and an act of cooking is an example of an occurrent.
gist is a business-focused upper-level ontology that has been developed over the last 15+ years and used in over 100 commercial implementations [10]. Ontology elements found in gist leverage everyday labels in the interest of facilitating stakeholder understanding to support rapid modeling. Much like BFO, gist contains a relatively small number of terms, relations, and formally specified axioms: It has 98 classes, 63 object properties, 50 datatype properties, and approximately 1400 axioms, at the time of this writing. Approximately 20 classes are at the highest level of the gist class hierarchy. Subclasses are defined using a distinctionary pattern,3 which includes using a subclass axiom along with disjointness axioms and property restrictions to distinguish a class from its parents and siblings. gist favors property restrictions over domain and range axioms to maintain generality and avoid a proliferation of properties [12]. Commonly used top level classes include gist:Commitment, gist:Event, gist:Organization, gist:PhysicalIdentifiableItem, and gist:Place.
Ontology alignments in general are useful because they allow interoperability between ontologies and consequently help prevent what has been called the ontology silo problem, which arises when ontologies covering the same domain are constructed independently from one another, using differing syntax and semantics [13]. Ontologists typically leverage the Resource Description Framework (RDF) and vocabularies extended from it, to maintain flexibility when storing data into graphs, which goes some way to address silo problems. If, however, data is represented in RDF using different ontologies, enriched with different semantics, then ontology silo problems emerge. Alignment between potential ontology silos can address this problem by allowing the data to be interpreted by each aligned ontology.
Needless to say, given the respective scopes of gist and BFO, as well as their overlapping users and domains, we have identified them as ontology silos worth aligning. For current users of gist, alignment provides a way to leverage BFO without requiring
2 We adopt the convention of displaying class names in bold, prepended with a namespace identifier indicating provenance. 3 The distinctionary pattern outlined in [11] is like the Aristotelian approach described in [1].
any additional implementation. For new users of gist, it provides a pragmatic base for building domain ontologies. This is of particular importance as BFO was recently adopted as a baseline standard in the U.S. Department of Defense and Intelligence Community [14]. For stakeholders in both the open and closed space, the alignment proposed here will allow users to model a domain in gist and align with other ontologies in the BFO ecosystem, satisfying the requirements of leveraging an ISO standard. In the other direction, users of BFO will be able to leverage domain representations in gist, gaining insights into novel modeling patterns, potential gaps in the ecosystem, and avenues for future modeling research.
2. Methodology
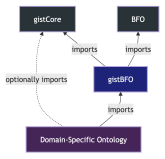
In this section we discuss the process we used to build what we call “gistBFO,” an ontology containing a semantic alignment between gist and BFO. We started by creating an RDF turtle file that would eventually contain all the mappings, and then manually worked out the connections between gist and BFO starting from the upper-level classes of both ontologies. We specified that our new ontology imports both the gist and BFO ontologies, complete with their respective terms and axioms. To make use of gistBFO, it can be imported into a domain ontology that currently uses gist.
Figure 1. gistBFO import hierarchy4
2.1. Design principles
To describe our methodology, it is helpful to distinguish between alignments and mappings [15]. By alignment we mean a set of assertions (or “triples”) of the form <s, p, o> that relate the terms of one ontology to another. gistBFO contains such an alignment. The individual assertions contained within an alignment are mappings.
4 This diagram is adapted from a similar diagram in [10].
gist:Specification subClassOf bfo:GenericallyDependentContinuant5 (bfo:GDC, hereafter) is an example of one mapping in gistBFO’s alignment [16]. By way of evaluation, we have designed gistBFO to exhibit a number of important properties: consistency, coherence, conservativity, specificity, and faithfulness [17]. An ontology containing an alignment is consistent just in case its mappings and the component ontologies do not logically entail a contradiction. For example, if a set of assertions entails both that Bird is equivalent to NonBird and that NonBird is equivalent to the complement of Bird, then it is inconsistent. Relatedly, such an ontology is coherent just in case all of its classes are satisfiable. In designing an ontology, a common mistake is creating an unsatisfiable class—a class that cannot have members on pain of a contradiction.6 Suppose a class A is defined as a subclass of both B and the complement of B. Anything asserted as a member of A would be inferred to be a member of B and its complement, resulting in a contradiction. Note that the definition of A itself does not result in a logical inconsistency; it is only when an instance is asserted to be a member of A that a contradiction is generated.
Consistency and coherence apply to gistBFO as a whole (i.e., the union of gist, BFO, and the alignment between them). The next several apply more specifically to the alignment.
An alignment is conservative just in case it does not add any logical entailments within the aligned ontologies.7 Trivially, gistBFO allows more to be inferred than either gist or BFO alone, since it combines the two ontologies and adds mapping assertions between them. However, it should not imply anything new within gist or BFO, which would effectively change the meanings of terms within the ontologies. For example, gist never claims that gist:Content subClassOf gist:Event. If gistBFO were to imply this, it would not only be ontologically suspect, but it would extend gist in a non-conservative manner, effectively changing the meaning of gist:Content. Similarly, BFO never claims that BFO:GDC subClassOf BFO:Process (again, for good reason); so if gistBFO were to imply this, this too would make it a non-conservative extension, changing the content of BFO itself. It is desirable for the alignment to be a conservative extension of gist and BFO so that it is not changing the meaning of terms within gist or BFO. By the same token, if gistBFO were to remove axioms from gist or BFO, it would need to be handled carefully so that it too preserves the spirit of the two ontologies. (More on this in Section 4.1.1.) Additionally, if gistBFO does not remove any axioms from gist or BFO, there is no need to maintain separate artifacts with modified axioms.
An alignment is specific to the extent that terms from the ontologies are related to the most specific terms possible. For example, one possible alignment between gist and BFO would contain mappings from each top-level gist class to bfo:Entity. While this would constitute a bonafide alignment by our characterization above, it is not an interesting or useful one. If it achieves BFO-compliance, it is only in a trivial sense. For this reason, we aimed to be specific with our alignment and mapped gist classes to the lowest BFO classes that were appropriate.
5 Strictly speaking, the IRI for generically dependent continuant in BFO is obo:BFO_0000031, but we use bfo:GenericallyDependentContinuant (and bfo:GDC for short). The actual subclass relation used in the alignment is rdfs:subClassOf, but the namespace prefix is dropped for brevity. 6 In OWL, unsatisfiable classes are subclasses of owl:Nothing, the class containing no members. It is analogous to the set-theoretic notion of “the empty set.” 7 See [17, p.3] for a more formal explanation of conservativity in the context of an alignment.
An alignment is faithful to the extent that it respects the intended meanings of the terms in each ontology. Intent is not always obvious, but it can often be gleaned from formal definitions, informal definitions/annotations, and external sources.
We aim in this work for gistBFO to exhibit the above properties. Note also that two ontologies are said to be synonymous just in case anything expressed in one ontology can be expressed in terms of the other (and vice versa) [18]. We do not attempt to establish synonymy with this alignment. First, for present purposes, our strategy is to model in gist and then move to BFO, not the other way around. Second, the alignment in its current form consists primarily of subclass assertions from gist classes to BFO classes. With an accurate subclassing bridge, instances modeled in gist would then achieve an initial level of BFO-compliance, as instances can be inferred into BFO classes. A richer mapping might be able to take an instance modeled in gist and then translate that entirely into BFO, preserving as much meaning as possible. For example, something modeled as a gist:Event with gist:startDateTime and gist:endDateTime might be modeled as a bfo:Process related to a bfo:TemporalRegion. We gesture at some more of these richer mappings in the Conclusion section, noting that our ultimate plan is to investigate these richer mappings in the future. So, while we do not attempt to establish synonymy between gist and BFO at present, we do have a goal of preserving as much meaning as possible in the alignment here, and plan to expand this work in the near future. In that respect, our work here provides a firm foundation for a richer, more complex, semantic alignment between gist and BFO.
Given our aim of creating a BFO-compliant version of gist, we have created a consistent, coherent, conservative, specific, and faithful ontology. Since both gist and BFO are represented in the OWL DL profile, consistency and coherence were established using HermiT, a DL reasoner [19, 20]. By running the reasoner, we were able to establish that no logical inconsistencies or unsatisfiable classes were generated. While it is undecidable in OWL 2 DL whether an alignment is a conservative extension, one can evaluate the approximate deductive difference by looking more specifically at the subsumption relations that hold between named classes in gist or BFO.8 We checked, for example, that no new entailments between gist classes were introduced. Specificity and faithfulness are not as easily measured, but we detail relevant design choices in the Discussion section as justification for believing our alignment exhibits these properties as well.
2.2. Identifying the mappings
The properties detailed in Section 2.1 give a sense of our methodological aims for gistBFO. Now we turn to our methods for creating the mappings within the alignment. In our initial development of the alignment, we leveraged the BFO Classifier [22]. Included in the BFO Classifier was a decision diagram that allowed us to take instances of gist classes, answer simple questions, and arrive at a highly plausible candidate superclass in BFO. For example, consider a blueprint for a home. In gist, a blueprint would fall under gist:Specification. To see where a blueprint might fall in BFO, we answered the following questions:
8 The set of changed subsumption entailments from combining ontologies with mappings has been called the approximate deductive difference [17, p.3; 21].
• Q: Does this entity persist in time or unfold in time? A: It persists. So, a blueprint is a bfo:Continuant.
• Q: Is this entity a property of another entity or depends on at least one other entity? A: Yes, a blueprint depends on another entity (e.g., a sheet of paper) to be represented.
• Q: May the entity be copied between a number of bearers? A: Yes, a blueprint can be copied across multiple sheets of paper. So, a blueprint is a bfo:GDC.
Given that blueprints are members of gist:Specification and bfo:GDC (at least according to our answer above), bfo:GDC was considered a plausible candidate superclass for gist:Specification. And indeed, as we think about all the possible instances of gist:Specification, they all seem like they would fall under bfo:GDC.
Our alignment was not conducted entirely by using the BFO Classifier. Our teams are constituted by lead developers, stakeholders, and users of both gist and BFO. Classification was refined through consensus-driven meetings, where the meanings of ontology elements in respective structures were discussed, debated, and clarified. Thus, while the BFO Classifier tool provided a very helpful starting point for discussions of alignment, thoughtful effort was put into identifying and verifying that the gist and BFO mappings exhibited the highest degree of accuracy.
Tables 1 and 2 contain a non-exhaustive list of important classes and definitions from gist and BFO that we refer to throughout the paper.
BFO Class Elucidation/Definition
Continuant An entity that persists, endures, or continues to exist through time while maintaining
its identity.
Independent
Continuant A continuant which is such that there is no x such that it specifically depends on x
and no y such that it generically depends on y.
Specifically
Dependent
Continuant A continuant which is such that (i) there is some independent continuant x that is not
a spatial region, and which (ii) specifically depends on x.
Generically
Dependent
Continuant An entity that exists in virtue of the fact that there is at least one of what may be
multiple copies.
Material Entity An independent continuant that at all times at which it exists has some portion of
matter as continuant part.
Immaterial Entity An independent continuant which is such that there is no time t when it has a
material entity as continuant part.
Object A material entity which manifests causal unity and is of a type instances of which
are maximal relative to the sort of causal unity manifested.
Occurrent An entity that unfolds itself in time or is the start or end of such an entity or is a
temporal or spatiotemporal region.
Process An occurrent that has some temporal proper part and for some time has a material
entity as participant.
Table 1. Selected BFO classes and definitions [6]
gist Class Elucidation/Definition
Event Something that occurs over a period of time, often characterized as an activity being
carried out by some person, organization, or software application or brought about
by natural forces.
Organization A generic organization that can be formal or informal, legal or non-legal. It can have
members, or not.
Building A relatively permanent man-made structure situated on a plot of land, having a roof
and walls, commonly used for dwelling, entertaining, or working.
Unit of Measure A standard amount used to measure or specify things.
Physical
Identifiable Item A discrete physical object which, if subdivided, will result in parts that are
distinguishable in nature from the whole and in general also from the other parts.
Specification One or more characteristics that specify what it means to be a particular type of
thing, such as a material, product, service or event. A specification is sufficiently
precise to allow evaluating conformance to the specification.
Intention Goal, desire, aspiration. This is the “teleological” aspect of the system that indicates
things are done with a purpose.
Temporal Relation A relationship existing for a period of time.
Category A concept or label used to categorize other instances without specifying any formal
semantics. Things that can be thought of as types are often categories.
Collection A grouping of things.
Is Categorized By Points to a taxonomy item or other less formally defined class.
Is Member Of Relates a member individual to the thing, such as a collection or organization, that it
is a member of.
Table 2. Selected gist classes and definitions [23]
3. Results
The gistBFO alignment contains 43 logical axioms. 35 of these axioms are subclass assertions relating gist classes to more general classes in BFO. All gist classes have a superclass in BFO.9 The remaining eight axioms are subproperty assertions. We focused on mapping key properties in gist (e.g., gist:isCategorizedBy and gist:isMemberOf) to BFO properties. While mapping gist properties to more specific properties in BFO does not serve the use case of starting with gist and inferring into BFO, it nevertheless provides a richer connection between the ontologies, which we view as a worthy goal.
In addition to these 43 logical axioms, gistBFO also contains annotations expressing the rationale behind some of the mapping choices. We created an annotation property gist:bfoMappingNote for this purpose.
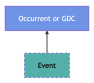
At the highest level, almost all classes in gist fall under bfo:Continuant, since their instances are things that persist through time rather than unfold over time. Exceptions to this are instances falling under gist:Event and its subclasses, which (generally) fall under bfo:Occurrent.
Some of the gist subclasses of bfo:Continuant include gist:Collection, gist:PhysicallyIdentifiableItem, and gist:Content. Within BFO, continuants break down into bfo:IndependentContinuant (entities that bear properties), bfo:GDC (copyable patterns that are often about other entities), and bfo:SDC (properties borne by independent continuants). With respect to our alignment, introduced subclasses of bfo:IndependentContinuant include gist:Building or gist:Component or other material entities like gist:PhysicalSubstance.10 Subclasses of bfo:GDC include gist:Content, gist:Language, gist:Specification, gist:UnitOfMeasure, and
9 An exception is gist:Artifact, which, in addition to being difficult to place in BFO, is slated for removal from gist. 10 Best practice in BFO is to avoid mass terms [1], whereas gist:PhysicalSubstance is intentionally designed to represent them—e.g., a particular amount of sand. Regardless, this class of mass terms would map into a subclass of bfo:IndependentContinuant.
gist:Template—all things that can be copied across multiple bearers.11 A subclass of bfo:SDC includes gist:TemporalRelation—a relational quality holding between multiple entities.
In most cases, the subclass assertions are simple in construction, relating a named class in gist to a named class in BFO, for example, gist:Specification subClassOf bfo:GDC. A more complex pattern involves the use of OWL property restrictions. For example, gist:ControlledVocabulary was asserted to be a subclass of bfo:GDCs that have some bfo:GDC as a continuant part.
gist:ControlledVocabulary
rdfs:subClassOf [
a owl:Class ;
owl:intersectionOf (
# class = bfo:GDC
obo:BFO_0000031
[
a owl:Restriction ;
# property = bfo:hasContinunantPart owl:onProperty obo:BFO_0000178 ; # class = bfo:GDC
owl:someValuesFrom obo:BFO_0000031 ;
]
) ; ] ; .
In other cases, we employed a union pattern—e.g., gist:Intention is a subclass of the union of bfo:SDC and bfo:GDC. Had we chosen a single named superclass in BFO for gist:Intention, it might have been bfo:Continuant. The union pattern, however, allows our mapping to exhibit greater specificity, as discussed above.
Figures 2 through 4 illustrate important subclass relationships between gist and BFO classes:

Figure 2. Continuants in gist
11 Many of these can be understood as various sorts of ‘information’, which should be classified under bfo:GDC. For example, units of measurement are standardized information which describe some magnitude of quantity.

Figure 3. Independent and dependent continuants in gist
Figure 4. gist:Event
4. Discussion
In this section we discuss in depth some specific mappings we made, focusing most closely on some challenging cases.
4.1.1. gist:Intention and gist:Specification
One challenging case was gist:Intention and its subclass gist:Specification. The textual definition of gist:Intention suggests it is a mental state that is plausibly placed under bfo:SDC. That said, the textual definition of gist:Specification (think of a blueprint) suggests this class plausibly falls under bfo:GDC. Given that bfo:SDC and bfo:GDC
are disjoint in BFO, this would result in a logical inconsistency. We thus appear to have encountered a genuine logical challenge to our mapping.
Exploring strategies for continuing our effort, we considered importing a “relaxed” version of BFO that drops the disjointness axiom between bfo:SDC and bfo:GDC. Arguably this option would respect the spirit of gist (by placing gist:Intention and gist:Specification in their true homes in BFO) while losing a bit of the spirit of BFO. While this may appear to be an unsatisfactory mapping strategy, we maintain that—if such relaxing of constraints are properly documented and tracked—there is considerable benefit in adopting such a strategy. Given two ontologies developed independently of one another, there are likely genuine semantic differences between them, differences that cannot be adequately addressed by simply adopting different labels. Clarifying, as much as possible, what those differences are can be incredibly valuable when representing data using each ontology structure. Putting this another way, if, say, gist and BFO exhibited some 1-1 semantic mapping so that everything in gist corresponds to something in BFO and vice versa, it would follow that the languages of gist and BFO were simply two
different ways to talk about the same domain. We find this less interesting, to be candid, than formalizing the semantic overlap between these structures, and noting precisely where they semantically differ. One way in which such differences might be recorded is by observing and documenting—as suggested in this option—where logical constraints such as disjointness might need to be relaxed in alignment.
The preceding stated, relaxing constraints should be the last, not the first, option pursued, since for the benefits highlighted above to manifest, it is incumbent on us to identify where exactly there is semantic alignment, and formalize this as clearly as possible. With that in mind, we pursue another option here, namely, to use a disjunctive definition for gist:Intention—asserted to be a subclass of the union of bfo:GDC and bfo:SDC. While this disjunctive definition perhaps does not square perfectly with the text definition of gist:Intention, it does seem to be in the spirit of how gist:Intention is actually used—sometimes like an bfo:SDC (in the case of a gist:Function), sometimes like a bfo:GDC (in the case of a gist:Specification). This option does not require a modified version of BFO. It also aligns with our goal of exhibiting specificity in our mapping, since otherwise we would have been inclined to assert gist:Intention to simply be a subclass of bfo:Continuant.
gist:Intention
rdfs:subClassOf [
a owl:Class ;
owl:unionOf (
obo:BFO_0000020 # bfo:SDC
obo:BFO_0000031 # bfo:GDC
);];.
This mapping arguably captures the spirit of both gist and BFO while remaining conservative—i.e., it does not change any of the logical entailments within gist or BFO.
4.1.2. gist:Organization
gist:Organization was another interesting case. During the mapping we consulted the Common Core Ontologies (CCO), a suite of mid-level ontologies extended from BFO, for guidance since it includes an organization class [24]. cco:Organization falls under bfo:ObjectAggregate. Arguably, however, organizations can be understood as something over and above the aggregate of their members, perhaps even persisting when there are no members. For this reason, we considered bfo:ImmaterialEntity and bfo:GDC as superclasses of gist:Organization. On the one hand, the challenge with asserting gist:Organization is a subclass of bfo:ImmaterialEntity is that instances of the latter cannot have material parts, and yet organizations often do, i.e. members. On the other hand, there is plausibly a sense in which organizations can be understood as, say, prescriptions or directions (bfo:GDC) for how members occupying positions in that organization should behave, whether there ever are actual members. The CCO characterization of organization does not seem to reflect this sense, given it is defined in terms of members. It was thus important for our team to clarify which sense, if either or both, was best reflected in gist:Organization.
Ultimately, we opted for asserting bfo:ObjectAggregate as the superclass for gist:Organization, as the predominant sense in which the latter is to be understood concerns members of such entities. This is, importantly, not to say there are not genuine
alternative senses of organization worth modeling in both gist and within the BFO ecosystem; rather, it is to say after reflection, the sense most clearly at play here for gist:Organization involves membership. For some gist classes, annotations and examples made it clear that they belonged under a certain BFO class. In the case of gist:Organization, gist is arguably neutral with respect to a few candidate superclasses. Typically what is most important in an enterprise context is modeling organizational structure (with sub-organizations) and organization membership. Perhaps this alone does not require gist:Organization being understood as a bfo:ObjectAggregate; nevertheless, practical considerations pointed in favor of it. Adopting this subclassing has the benefit of consistency with CCO (and a fortiori BFO) and allows for easy modeling of organization membership in terms of BFO.
4.1.3. gist:Event
At a first pass, a natural superclass (or even equivalent class) for gist:Event is bfo:Process. After all, ‘event’ is an alternative label for bfo:Process in BFO. Upon further evaluation, it became clear that some instances of gist:Event would not be instances of bfo:Process—namely, future events. In BFO, with its realist interpretation, processes have happened if they are to be represented. It is in this way that BFO differentiates how the world could be, e.g., this portion of sodium chloride could dissolve, from how the world is, e.g., this portion of sodium chloride dissolves. Future events can be modeled as specifications, ultimately falling under bfo:GDC. In contrast, a subclass of gist:Event, namely gist:ScheduledEvent, includes within its scope events that have not yet started. There is thus not a straightforward mapping between bfo:Process and gist:Event. Following our more conservative strategy, however, the identified discrepancy can be accommodated by asserting that gist:Event is a defined subclass of the union of bfo:GDC and bfo:Process.12 In this respect, we are able to represent instances of gist:Event that have started (as instances of bfo:Process) and those that have not (as instances of bfo:GDC).
gist:Event
rdfs:subClassOf [
a owl:Class ;
owl:unionOf (
obo:BFO_0000031 # bfo:GDC
obo:BFO_0000015 # bfo:Process
);];.
4.1.4. gist:Category
gist:Category is a commonly used class in gist. It allows one to categorize an entity without introducing a new class into an ontology. It guards against the proliferation of classes with little or no semantics; instead, such categories are treated as instances, which
12It is common in gist to model planned-event-turned-actual-events as single entities that persist through both stages. When a plan goes from being merely planned to actually starting, it can flip from a bfo:GDC to a bfo:Process. Events that have a gist:actualStartDateTime will be instances of bfo:Process, and the presence of this property could be used to automate the flip. Different subclasses of gist:Event will be handled differently—e.g., gist:HistoricalEvent is a subclass of bfo:Process that would not require the transition from bfo:GDC.
are related to entities by a predicate gist:isCategorizedBy. So, for example, one might have an assertion like ex:_Car_1 gist:isCategorizedBy ex:_TransmissionType_manual, where the object of this triple is an instance of ex:TransmissionType, which would be a subclass of gist:Category.
If one thinks of BFO as an ontology of particulars, and if instances of gist:Category are not particulars but instead types of things, then arguably gist:Category does not have a home in BFO.
Nevertheless, as a commonly-used class in gist, it is helpful to find a place for it in BFO if possible. One option is bfo:SDC: indeed, there are some classes in CCO (e.g., cco:EyeColor) that seem like they could be subclasses of gist:Category. However, instances of bfo:SDC (e.g., qualities and dispositions) are individuated by the things that bear them (e.g., the eye color of a particular person), which does not seem to capture the spirit of gist:Category. Ultimately, we opted for bfo:GDC as the superclass in part because of the similarity of instances of gist:Category to information content entities in CCO, which are bfo:GDCs.
5. Conclusion
5.1. Future work
We have established a foundational mapping between gist and BFO. From this foundation going forward we aim to improve gistBFO along multiple dimensions. The first set of improvements relate to faithfulness. While we are confident in many of the mappings we have made, we expect the alignment to become more and more accurate as we continue development. In some cases, the intended meanings of concepts are obvious from formal definitions and annotations. In other cases, intended meaning is best understood by discussions about how the concepts are used in practice. As we continue discussions with practitioners of gist and BFO, the alignment will continue to improve.
Another aim related to faithfulness is to identify richer mappings. In its current form gistBFO allows instance data modeled under gist to be inferred into BFO superclasses. While this achieves an initial connection with BFO, a deeper mapping could take something modeled in gist and translate it to BFO. Revisiting the previous example, something modeled as a gist:Event with gist:startDateTime and gist:endDateTime
might be modeled as a bfo:Process related to a bfo:TemporalRegion. Many of these types of modeling patterns can be gleaned from formal definitions and annotations, but they do not always tell the whole story. Again, this is a place where continued discussions with practitioners of both ontologies can help. From a practical perspective, more complex mappings like these could be developed using a rule language (e.g., datalog or SWRL) or SPARQL INSERT queries.
We have also considered alignment with the Common Core Ontologies (CCO). One of the challenges with this alignment is that gist and CCO sit at similar levels of abstraction. Indeed, gist and CCO even appear to share classes that exhibit overlapping semantics, e.g., language and organization. The similar level of abstraction creates a challenge because it is not always easy to determine which classes are more general than which. For example, are gist:Organization and cco:Organization equivalent, or is one a superclass of the other? Furthermore, because there are considerably more classes in CCO than BFO, preserving consistency with a growing set of alignment axioms becomes
more of a concern. Despite the challenges, a mapping between gist and CCO would help with interoperability, and it is a topic we intend to pursue in the future to that end.
5.2. Final remarks
We have presented an open-source alignment between gist and BFO. We described a methodology for identifying mappings, provided rationale for the mappings we made, and outlined a vision for future development. Our hope is that gistBFO can serve as a practical tool, promoting easier domain ontology development and enabling interoperability.
Acknowledgements
Thank you to Dave McComb for support at various stages of the gistBFO design process, from big-picture discussions to input on specific mappings. Thanks also to Michael Uschold and Ryan Hohimer for helpful discussions about gistBFO.
References
[1] Arp R, Smith B, Spear AD. Building ontologies with Basic Formal Ontology. Cambridge, Massachusetts: The MIT Press; 2015. p. 220
[2] Hoehndorf R, Schofield PN, Gkoutos GV. The role of ontologies in biological and biomedical research: a functional perspective. Brief Bioinform. 2015 Nov;16(6):1069–80, doi: 10.1093/bib/bbv011 [3] Neuhaus F, Hastings J. Ontology development is consensus creation, not (merely) representation. Applied Ontology. 2022;17(4):495-513, doi:10.3233/AO-220273
[4] Chen X, Jia S, Xiang Y. A review: Knowledge reasoning over knowledge graph. Expert Systems with Applications. 2020 Mar;141:112948, doi:10.1016/j.eswa.2019.112948
[5] Basic Formal Ontology Users [Internet]. Available from: https://basic-formal-ontology.org/users.html [6] GitHub [Internet]. Basic Formal Ontology (BFO) Wiki – Home. Available from: https://github.com/BFO ontology/BFO/wiki/Home
[7] ISO/IEC 21838-1:2021: Information technology — Top-level ontologies (TLO) Part 1: Requirements [Internet]. Available from: https://www.iso.org/standard/71954.html
[8] ISO/IEC 21838-2:2021: Information technology — Top-level ontologies (TLO) Part 2: Basic Formal Ontology (BFO) [Internet]. Available from: https://www.iso.org/standard/74572.html [9] Otte J, Beverley J, Ruttenberg A. Basic Formal Ontology: Case Studies. Applied Ontology. 2021 Aug;17(1): doi:10.3233/AO-220262
[10] McComb D. A BFO-ready Version of gist [Internet]. Semantic Arts. Available from: https://www.semanticarts.com/wp-content/uploads/2025/01/20241024-BFO-and-gist-Article.pdf [11] McComb D. The Distictionary [Internet]. Semantic Arts. 2015 Feb. Available from: https://www.semanticarts.com/white-paper-the-distinctionary/
[12] Carey D. Avoiding Property Proliferation [Internet]. Semantic Arts. Available from: https://www.semanticarts.com/wp-content/uploads/2018/10/AvoidingPropertyProliferation012717.pdf [13] Trojahn C, Vieira R, Schmidt D, Pease A, Guizzardi G. Foundational ontologies meet ontology matching: A survey. Semantic Web. 2022 Jan 1;13(4):685–704, doi.org/10.3233/SW-210447
[14] Gambini B, Intelligence Community adopt resource developed by UB ontologists [Internet]. News Center. 2024 [cited 2025 Mar 30]. Available from: https://www.buffalo.edu/news/releases/2024/02/department-of-defense-ontology.html
[15] Euzenat J, Shvaiko P. Ontology Matching, 2nd edition. Heidelberg: Springer; 2013. doi:10.1007/978-3- 642-38721-0.
[16] GitHub [Internet]. Available from: https://github.com/semanticarts/gistBFO
[17] Prudhomme T, De Colle G, Liebers A, Sculley A, Xie P “Karl”, Cohen S, Beverley J. A semantic approach to mapping the Provenance Ontology to Basic Formal Ontology. Sci Data. 2025 Feb 17;12(1):282, doi:10.1038/s41597-025-04580-1
[18] Aameri B, Grüninger M. A New Look at Ontology Correctness. Logical Formalizations of Commonsense Reasoning. Papers from the 2015 AAAI Spring Symposium; 2015. doi:10.1613/jair.5339
[19] Shearer R, Motik B, Horrocks I. HermiT: A highly-efficient OWL reasoner. OWLED, 2008, Available from: https://ceur-ws.org/Vol-432/owled2008eu_submission_12.pdf.
[20] Glimm B, Horrocks I, Motik B, Stoilos G, Wang Z. HermiT: an OWL 2 reasoner. Journal of Automated Reasoning. 2014;53:245–269, doi:10.1007/s10817-014-9305-1
[21] Solimando A, Jiménez-Ruiz E, Guerrini G. Minimizing conservativity violations in ontology alignments: algorithms and evaluation. Knowl Inf Syst. 2017;51:775–819, doi:10.1007/s10115-016-0983-3 [22] Emeruem C, Keet CM, Khan ZC, Wang S. BFO Classifier: Aligning Domain Ontologies to BFO. 8th Joint Ontology Workshops; 2022.
[23] GitHub [Internet]. gist. https://github.com/semanticarts/gist
[24] Jensen M, De Colle G, Kindya S, More C, Cox AP, Beverley J. The Common Core Ontologies. 14th International Conference on Formal Ontology in Information Systems; 2024: doi:10.48550/arXiv.2404.17758.