
Gist is designed to have the maximum coverage of typical business ontology concepts with the fewest number of primitives and the least amount of ambiguity, known as a minimalist
upper ontology.
A title guaranteed to scare off just about everyone; if you’re not familiar with work on upper ontologies, the title is just opaque. If you are familiar, you’ll likely think that the combination of “minimalist” with “upper ontology” is an oxymoron. So, now that I’ve gotten rid of all my audience, I can probably say just about anything. And will. Let’s review our position here. For two systems to communicate they must commit to a common ontology. It doesn’t matter how elegant or clever your ontology is, if no one else shares it, you don’t participate in anything broader than your own ontology. Given that there are three main positions:
- Wait until you want to integrate, and then build a bridge ontology. This works, but is numerically exhaustive if you have a lot of other ontologies to link to.
- Integrate on a topic by topic basis. Use a set of special purpose ontologies to link up. This is a reasonable strategy and works for a lot of things (geography for instance).
- Commit to an upper ontology early. If you commit to a very broad upper ontology, you are conceptually linked to anyone else who does.
For some that third strategy is very appealing. And there are some options to choose from here, most notably Cyc and SUMO. But, there is also a dark side. Any time you commit to an ontology, you agree to be bound by all the assertions made in that ontology. If nothing else, you need to review them, understand them, and determine whether committing to them will cause problems.
As a result, the most popular shared ontologies to date have been narrow scope upper ontologies, such as Dublin Core for documents, FoaF for contact lists and interests, and RSS for news feeds. What they all share is a small set of concepts, and relatively few constraints. I have postulated, built and will present what I call a “minimalist upper ontology” called, Gist. Gist is very broad in scope, comparable to the large upper ontologies (in this case I am trying to cover commercial information systems, so most of the corporate and government systems, but not games, compilers, embedded or scientific systems). But I have tried to mimic the size of the more popular ontologies: there are about 50 concepts in this ontology.
I believe there are immediate benefits for projects adopting it just to remove ambiguity from their definitions. But longer term I think it sets a basis for much broader scale cooperation. I think I’m on to something here. And it will only be of value if it is shared. The Gist ontology is available for free download at https://www.semanticarts.com/gist/

 great deal of time in elegant designs and even plans. But until and unless the architecture gets implemented it isn’t anything at all; it’s just a picture. What does get implemented has an architecture. It may not be very good architecture. It may not lend itself to easy modification or upgrade or any of the many virtues that we desire in our “architected” solutions. But it is architecture.
great deal of time in elegant designs and even plans. But until and unless the architecture gets implemented it isn’t anything at all; it’s just a picture. What does get implemented has an architecture. It may not be very good architecture. It may not lend itself to easy modification or upgrade or any of the many virtues that we desire in our “architected” solutions. But it is architecture.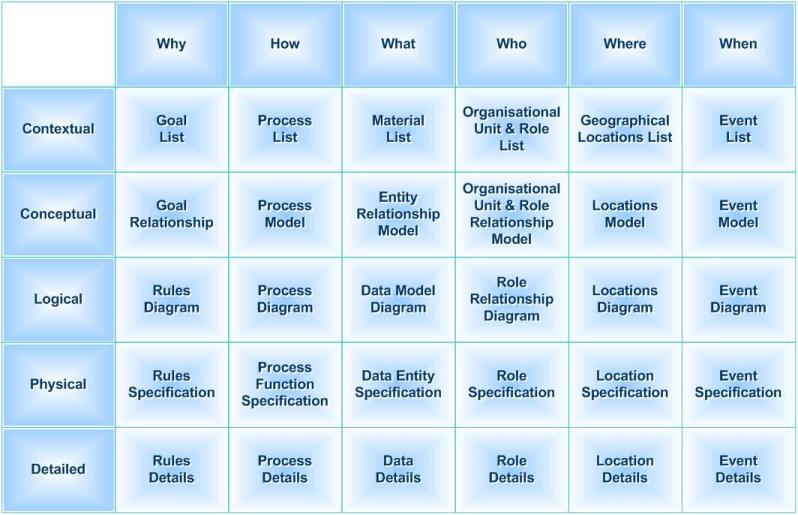
 sides of the same coin. But in the final examination, we find that they are intimately intertwined but still separate and potentially independent. The motivation for this paper was an observation that much of our work deals with system planning of some variety. And yet, there is virtually nothing on a web site on this topic.
sides of the same coin. But in the final examination, we find that they are intimately intertwined but still separate and potentially independent. The motivation for this paper was an observation that much of our work deals with system planning of some variety. And yet, there is virtually nothing on a web site on this topic. (I’m indebted to another author for this insight, but unfortunately I cannot credit him or her because I’ve lost the reference and can’t find it either in my pile of papers I call an office, nor on the Internet. So, if anyone is aware whose insight this was, please let me know so I can acknowledge them.)
(I’m indebted to another author for this insight, but unfortunately I cannot credit him or her because I’ve lost the reference and can’t find it either in my pile of papers I call an office, nor on the Internet. So, if anyone is aware whose insight this was, please let me know so I can acknowledge them.)