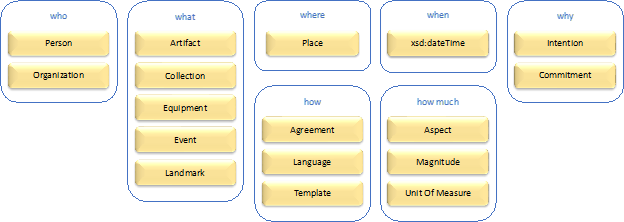
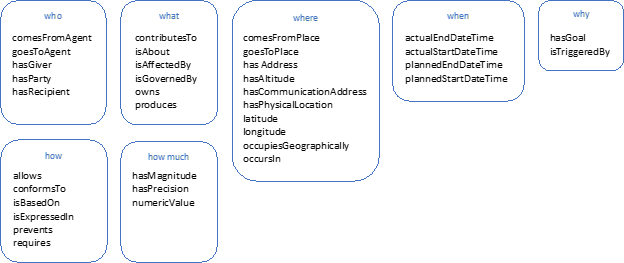
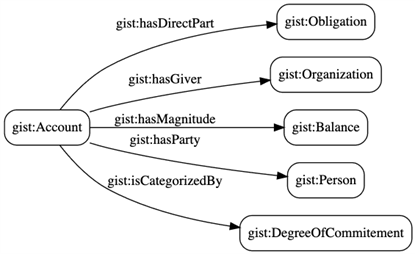
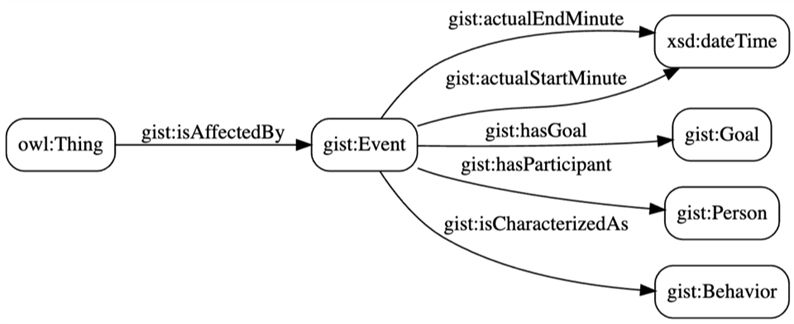
This blog post is for anyone interested in understanding units of measure for the physical world.
The dominant standard for units of measure is the International System of Units, part of a collaborative effort that describes itself as:
Working together to promote and advance the global comparability of measurements.
While the International System of Units is defined in a document, QUDT has taken the next step and defined an ontology and a set of reference data that can be queried via a public SPARQL endpoint. QUDT provides a wonderful resource for data-centric efforts that involve quantitative data.
QUDT is an acronym for Quantities, Units, Dimensions, and Types. With 72 classes and 178 properties in its ontology, QUDT may at first appear daunting. In this note, we will use a few simple SPARQL queries to explore the QUDT graph. The main questions we will answer are:
- What units are applicable for a given measurable characteristic?
- How do I convert a value from one unit to another?
- How does QUDT support dimensional analysis?
- How can units be defined in terms of the International System of Units?
Let’s jump right in. Please follow along as a hands-on exercise. Pull up the QUDT web site at:
https://qudt.org/
On the right side of the QUDT home page select the link to the QUDT SPARQL Endpoint where we can run queries:

From the SPARQL endpoint, select the query option.
Question 1: What units are applicable for a given measurable characteristic?
First, let’s at the measurable characteristics defined in QUDT. Copy-paste this query into the SPARQL endpoint:
prefix qudt: <http://qudt.org/schema/qudt/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix owl: <http://www.w3.org/2002/07/owl#>
prefix xsd: <http://www.w3.org/2001/XMLSchema#>
select ?qk
where {?qk rdf:type qudt:QuantityKind . }
order by ?qk
QUDT calls the measurable characteristics QuantityKinds.
Note that there is a Filter box that lets us search the output.

Type “acceleration” into the Filter box and then select the first value, Acceleration, to get a new tab showing the properties of Acceleration. Voila, we get a list of units for measuring acceleration:

Now to get a complete answer to our first question, just add a line to the query:
prefix qudt: <http://qudt.org/schema/qudt/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix owl: <http://www.w3.org/2002/07/owl#>
prefix xsd: <http://www.w3.org/2001/XMLSchema#>
select ?qk ?unit
where {
?qk rdf:type qudt:QuantityKind ;
qudt:applicableUnit ?unit ; # new line
.
}
order by ?qk ?unit
The output shows the units of measure for each QuantityKind.
Question 2: How do I convert a value from one unit to another?
Next, let’s look at how to do a unit conversion from feet to yards, with meter as an intermediary:

To convert from feet to meters, multiply by 0.3048. Then to convert from meters to yards, divide by 0.9144. Therefore, to convert from feet to yards, first multiply by 0.3048 and then divide by 0.9144. For example:
27 feet = 27 x (0.3048/0.9144) yards
= 9 yards
The 0.3048 and 0.9144 are in QUDT as the conversionMultipliers of foot and yard, respectively. You can see them with this query:
prefix qudt: <http://qudt.org/schema/qudt/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix owl: <http://www.w3.org/2002/07/owl#>
prefix xsd: <http://www.w3.org/2001/XMLSchema#>
select ?unit ?multiplier
where {
values ?unit {
<http://qudt.org/vocab/unit/FT>
<http://qudt.org/vocab/unit/YD> }
?unit qudt:conversionMultiplier ?multiplier .
}
This example of conversionMultipliers answers our second question; to convert values from one unit of measure to another unit of measure, first multiply by the conversionMultiplier of the “from” unit and then divide by the conversionMultiplier of the “to” unit. [note: for temperatures, offsets are also needed]
Question 3: How does QUDT support dimensional analysis?
To answer our third question we will start with a simple example:
Force = mass x acceleration
In the following query, we retrieve the exponents of Mass, Acceleration, and Force to validate that Force does indeed equal Mass x Acceleration:
prefix qudt: <http://qudt.org/schema/qudt/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix owl: <http://www.w3.org/2002/07/owl#>
prefix xsd: <http://www.w3.org/2001/XMLSchema#>
select ?qk ?dv ?exponentForMass ?exponentForLength ?exponentForTime
where {
values ?qk {
<http://qudt.org/vocab/quantitykind/Mass>
<http://qudt.org/vocab/quantitykind/Acceleration>
<http://qudt.org/vocab/quantitykind/Force> }
?qk qudt:hasDimensionVector ?dv .
?dv qudt:dimensionExponentForMass ?exponentForMass ;
qudt:dimensionExponentForLength ?exponentForLength ;
qudt:dimensionExponentForTime ?exponentForTime ;
.
}
Recall that to multiply “like terms” with exponents, add the exponents, e.g.
length1 x length2 = length3
In the QUDT output, look at the columns for Mass, Length, and Time. Note that in each column the exponents associated with Mass and Acceleration add up to the exponent associated with Force, as expected.
Question 4: How can units be defined in terms of the International System of Units?
Finally, we want to see how QUDT can be used to define units in terms of the base units of the International System of Units as defined in the SI Brochure. We want to end up with equations like:
1 inch = 0.0254 meters
1 foot per second squared = 0.3048 meters per second squared
1 pound per cubic yard = 0.5932764212577829 kilograms per cubic meter
Delving deeper into QUDT, we see the concept of QuantityKindDimensionVector. Every unit and every quantity kind is related to one of these QuantityKindDimensionVectors.
Let’s unpack what that means by way of an example where we show the dimension vector A0E0L1I0M0H0T-2D0 means Length x Time-2 (linear acceleration):
Start with dimension vector: A0E0L1I0M0H0T-2D0
Each letter stands for a base dimension, and the vector can also be written as:
Amount0 x ElectricCurrent0 x Length1 x Intensity0 x Mass0 x Heat0 x Time-2 x Other0
Every term with an exponent of zero equals 1, so this expression can be reduced to:
Length x Time-2 (also known as Linear Acceleration)
The corresponding expression in terms of base units of the International System of Units is:
Meter x Second-2 (the standard unit for acceleration)
… which can also be written as:
meter per second squared
Using this example as a pattern, we can proceed to query QUDT to get an equation for each QUDT unit in terms of base units. To reduce the size of the query we will focus on mechanics, where the base dimensions are Mass, Length, and Time and the corresponding base units are kilogram, meter, and second.
Here is the query to create the equations we want; run it on the QUDT SPARQL Endpoint and see what you get:
prefix qudt: <http://qudt.org/schema/qudt/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix owl: <http://www.w3.org/2002/07/owl#>
prefix xsd: <http://www.w3.org/2001/XMLSchema#>
select distinct ?equation
where {
?unit rdf:type qudt:Unit ;
qudt:conversionMultiplier ?multiplier ;
qudt:hasDimensionVector ?dv ;
rdfs:label ?unitLabel ;
.
?dv qudt:dimensionExponentForMass ?expKilogram ; # translate to units
qudt:dimensionExponentForLength ?expMeter ;
qudt:dimensionExponentForTime ?expSecond ;
rdfs:label ?dvLabel ;
.
filter(regex(str(?dv), “A0E0L.*I0M.*H0T.*D0”)) # mechanics
filter(!regex(str(?dv), “A0E0L0I0M0H0T0D0”))
filter(?multiplier > 0)
bind(str(?unitLabel) as ?unitString)
# to form a label for the unit:
# put positive terms first
# omit zero-exponent terms
# change exponents to words
bind(if(?expKilogram > 0, concat(“_kilogram_”, str(?expKilogram)), “”) as ?SiUnitTerm4)
bind(if(?expMeter > 0, concat(“_meter_”, str(?expMeter)), “”) as ?SiUnitTerm5)
bind(if(?expSecond > 0, concat(“_second_”, str(?expSecond)), “”) as ?SiUnitTerm7)
bind(if(?expKilogram < 0, concat(“_kilogram_”, str(-1 * ?expKilogram)), “”) as ?SiUnitTerm104)
bind(if(?expMeter < 0, concat(“_meter_”, str(-1 * ?expMeter)), “”) as ?SiUnitTerm105)
bind(if(?expSecond < 0, concat(“_second_”, str(-1 * ?expSecond)), “”) as ?SiUnitTerm107)
bind(concat(?SiUnitTerm4, ?SiUnitTerm5, ?SiUnitTerm7) as ?part1)
bind(concat(?SiUnitTerm104, ?SiUnitTerm105, ?SiUnitTerm107) as ?part2)
bind(if(?part2 = “”, ?part1,
if(?part1 = “”, concat(“per”,?part2),
concat(?part1, “_per”, ?part2))) as ?SiUnitString1)
bind(replace(?SiUnitString1, “_1_|_1$”, “_”) as ?SiUnitString2)
bind(replace(?SiUnitString2, “_2_|_2$”, “Squared_”) as ?SiUnitString3)
bind(replace(?SiUnitString3, “_3_|_3$”, “Cubed_”) as ?SiUnitString4)
bind(replace(?SiUnitString4, “_4_|_4$”, “ToTheFourth_”) as ?SiUnitString5)
bind(replace(?SiUnitString5, “_5_|_5$”, “ToTheFifth_”) as ?SiUnitString6)
bind(replace(?SiUnitString6, “_6_|_6$”, “ToTheSixth_”) as ?SiUnitString7)
bind(replace(?SiUnitString7, “_7_|_7$”, “ToTheSeventh_”) as ?SiUnitString8)
bind(replace(?SiUnitString8, “_8_|_8$”, “ToTheEighth_”) as ?SiUnitString9)
bind(replace(?SiUnitString9, “_9_|_9$”, “ToTheNinth_”) as ?SiUnitString10)
bind(replace(?SiUnitString10, “_10_|_10$”,”ToTheTenth_”) as ?SiUnitString11)
bind(replace(?SiUnitString11, “^_”, “”) as ?SiUnitString12) # tidy up
bind(replace(?SiUnitString12, “_$”, “”) as ?SiUnitString13)
bind(?SiUnitString13 as ?SiUnitLabel)
bind(concat(“1 “, str(?unitLabel), ” = “, str(?multiplier), ” “, ?SiUnitLabel) as ?equation)
}
order by ?equation
The result of this query is a set of equations that tie more than 1200 units back to the base units of the International System of Units, which in turn are defined in terms of seven fundamental physical constants.
And that’s a wrap. We answered all four questions with only 3 QUDT classes and 6 QUDT properties:
- What units are applicable for a given measurable characteristic?
- How do I convert a value from one unit to another?
- How does QUDT support dimensional analysis?
- How can units be defined in terms of the International System of Units?
For future reference, here’s a map of the territory we explored:

One final note: kudos to everyone who contributed to QUDT; it has a lot of great information in one place. Thank you!